- Full-text imaging and OCR-ing of books is okay if you do it for someone who owns a copy of that book and won’t use the scanned version to infringe the author’s rights. Permitting the public to search the full text of the book falls within the fair use doctrine, provided the search results you provide are of only small portions of the book, do not substantially harm the market for the book (such as when an entire recipe is revealed from a cookbook), and you don't make money from the process.
This all seems quite reasonable, and may provide some new guidance for fair use advocates. Its very reasonableness, however, makes it a wee bit suspect, since much of the existing law of copyright has very little to do with reasonableness and very much to do with what major content owners think it should be.
If the Supreme Court considers and upholds the Second Circuit decision, look for content owners to lobby Congress for a legislative “fix” that will close what I’m sure many will consider to be an undesirable result.
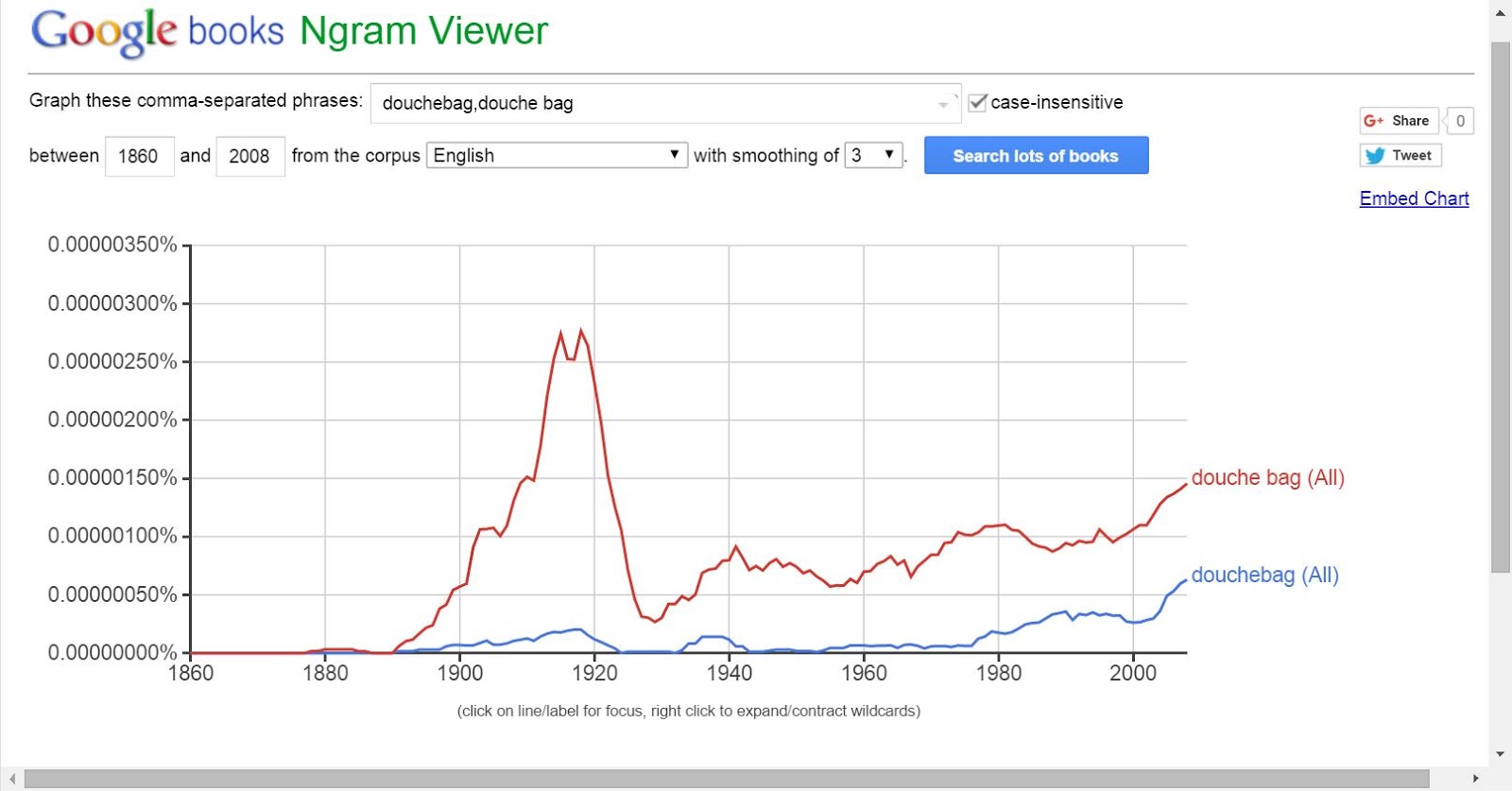
In the meantime, my personal takeaway from the Google Books decision is the existence of the Google Ngram viewer, which charts the frequency of word use over time among the many books that Google has scanned. In the interest of scholarship, I offer the results of my own thoughtful exploration of this feature below.

No comments:
Post a Comment